Sharing is Caring: Insecure Deserialization of Shared References in C++
Exploring a hidden attack surface in C++ serialization libraries. "Let's serialize pointers and complex structures! What could possibly go wrong?"
There where it is we do not need the wall:
He is all pine and I am apple orchard.
My apple trees will never get across
And eat the cones under his pines, I tell him.
He only says, ‘Good fences make good neighbors.’— Extract from Mending Wall by Robert Frost
This research was presented during BSidesHK 26. Check out the slides here!
Deserialization attacks have grown in popularity over the past decade, with major flaws hitting tech giants and modern frameworks— even in 2025.
Last July, a question came to mind: "What if we took insecure deserialization and brought it to C++?" I’ve had fond memories using .NET and PHP deserialization attacks to pop shells in CTFs, courses, and engagements, plus I enjoy tinkering with C++, so I decided to spend some personal time investigating this topic. Exploring this simple question resulted in a few late nights and an interesting— to my knowledge, novel— subclass of bugs.
This post presents my latest research, in which we’ll explore proof-of-concepts, do a bit of root cause analysis, and touch on Rust. I've also shared an advisory for those looking to remediate.

tl;dr
- What: Deserialization bugs were discovered across five C++ serialization libraries, potentially impacting downstream libraries and applications used across finance, science, IoT, and robotics.
- How: These libraries feature serialization of shared pointers/references— objects can reference other objects within an archive. Due to insufficient runtime type checking, an attacker could force objects of different types to share the same memory, opening the door to type confusion and memory corruption primitives.
- Impact: Information disclosure, control flow hijacking, heap corruption; all potentially leading to arbitrary code execution.
- Who is impacted? Conditions apply. For a detailed guide, you may wish to skip to the advisory.
- A hidden subclass of bugs? These aren’t your run-of-the-mill deserialization bugs common in .NET, PHP, or Java. Here, we have little control over the type deserialized and have no means to automatically execute code. The attack path is very different, and more akin to binary exploitation.
Insecure Deserialization Redux
When discussing insecure deserialization attacks, we typically think of a number of things: dynamic reflection, gadgets, POP chains, sweet sweet RCE. In Java and .NET, insecure deserialization features dynamic reflection, allowing arbitrary class construction and method invocation, leading to RCE. In PHP, insecure deserialization involves abusing code written in special __wakeup and construct() methods, which may lead to RCE.
But C++ only offers static reflection, and there is no automatic execution of untrusted data. Popular deserialization attacks won’t cut it; we need to rethink our approach in the context of a statically-typed, low-level language. What is a mechanism to exploit? What are our primitives? Can we still get that scrumptious RCE?
In the world of binary exploitation, primitives and gadgets exist in a low-level form. Instead of file read or file write, we think in terms of memory read and memory write. Instead of class or method-level gadgets, we have assembly-level gadgets.
As with other languages, we start by assuming the serialized payload is attacker-controllable. From here, the deserialization API is an attack surface.1 Our attention then turns to finding the functions and conditions necessary for exploitation.
How are references serialized?
While noodling around, I realized a few libraries have an interesting feature: serialization of references. The concept is also described as “object identity preservation”, “object tracking”, “pointer serialization”, or “reference sharing”.
To understand this feature, let’s consider the following example:
Alice and Bob share an address. What would serialization look like?
Serialization libraries tend to take one of two approaches. Either duplicate the data and serialize address twice; or preserve the structure and serialize address once. Both implementations have their tradeoffs, but it is the latter we are concerned with.
To preserve structure, it becomes necessary to have some referencing mechanism in the archive format. Let’s slightly modify the example:
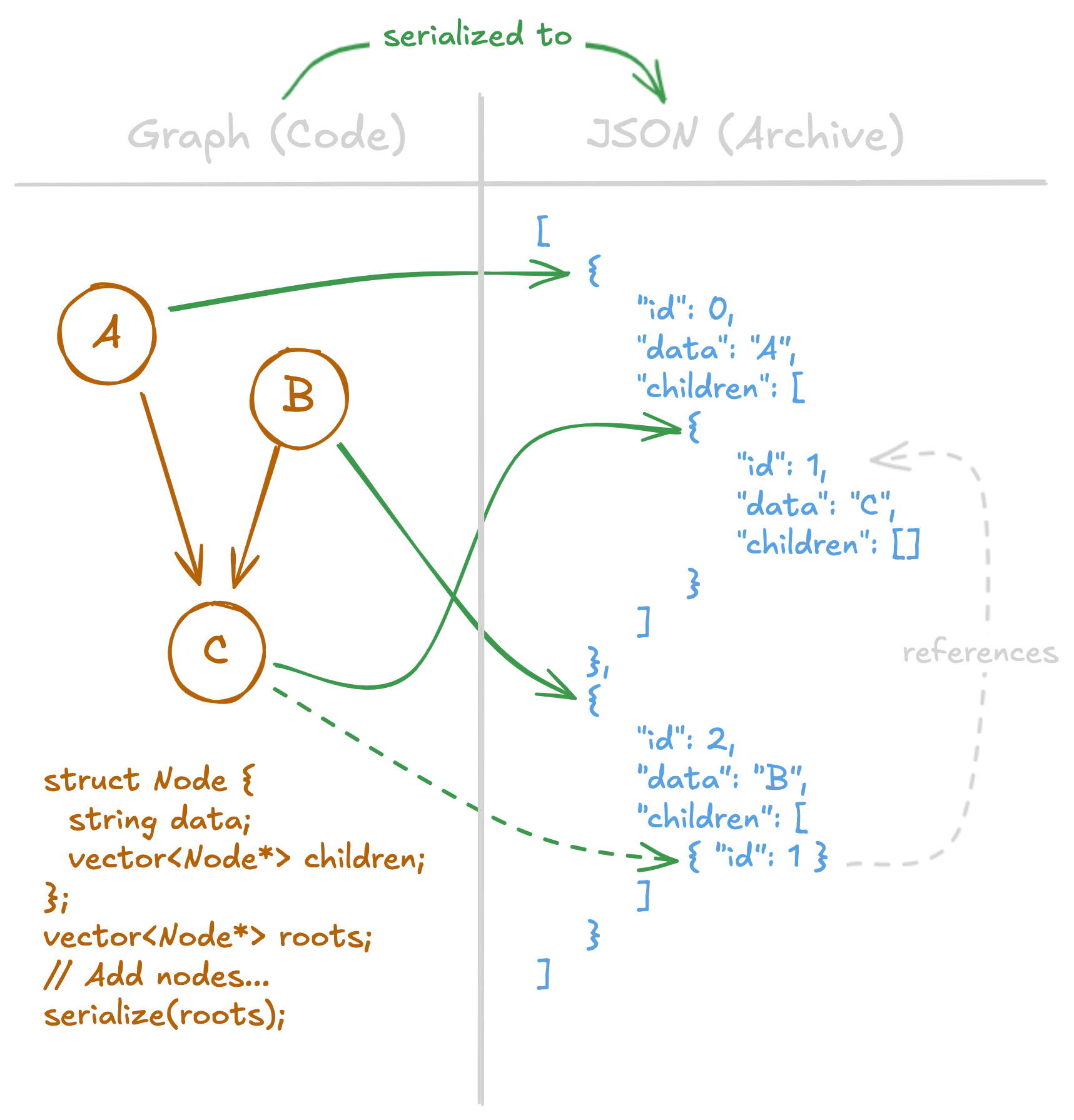
On the left, we have a simple graph represented in code and memory. On the right, we have its serialization in a contrived JSON format. Each node’s data is serialized once. Note that while C appears to be serialized twice, the second instance is merely a reference to the first. In this contrived serialization format, we use the id field to denote an object's identity.
What does deserialization look like? On the first encounter of an ID, the contents are deserialized and the ID is associated with the object. On subsequent encounters, the previous object is reused.
Given this example, the hacker in you may wonder:
- What if
idis negative or too large? - What if the JSON parser is buggy?
- What if we deserialize a cyclical graph?
- What if a pointer/reference refers to an object with a completely different type? (i.e. We change the scenario to serialize the code serializes other types and not just the
Nodetype.) - What if the referencing mechanism could be applied to non-referencing types?
All of these are potential attack vectors on the deserialization API. Some may lead to boring classic out-of-bound reads. Some may lead to DoS. In this post, we'll concern ourselves only with the last few questions, which put simply is this: Can we abuse the referencing mechanism?
Who uses pointer/reference serialization?
Pointer serialization is often used in low-latency, decentralised, and distributed systems. In industry, this means use cases span cross-process communication (IPC/RPC), finance, cryptocurrency, IoT, robotics, and science. These are systems which require moving data across machines while preserving the data structure.
I found five C++ libraries which support this feature, namely Boost Serialization, Cereal, Bitsery, and HPX. Other C++ serialization libraries exist such as nhlomann/json, or even popular language-agnostic libraries such as protobuf and msgpack. However, those libraries don't appear to support serialization of references, so we consider out-of-scope for this post.
- Boost Serialization. Boost is a popular C++ library which extends the standard library with various classes and features. Boost Serialization, born in 2003, is only one module among a plethora of modules and supports features including versioning, multiple archive formats (binary, text, XML), and serialization support for numerous standard types.
- Cereal is a slightly modern rehash of Boost Serialization, catering to C++11 features and modern formats such as JSON.
- HPX is an implementation of the C++ standard template library (STL) designed for high-performance computing (HPC). HPX contains a serialization module meant for message passing across a distributed system. It’s also based on Boost Serialization, but drops support for text-based formats in favor of the speedier binary formats. It also drops support for raw pointers.
- Bitsery is a serialization library which uses a custom binary format. It has a unique approach to serializing pointers, emphasising ownership.
- Cista is a serialization library featuring zero-copy deserialization and uses a binary serialization format. The concept of zero-copy deserialization is an important differentiator, affecting not only the API usage but also the attack surface and potential vulnerability impact. More on this later.
- rkyv is a Rust library supporting zero-copy deserialization, similar to Cista. More on this later.
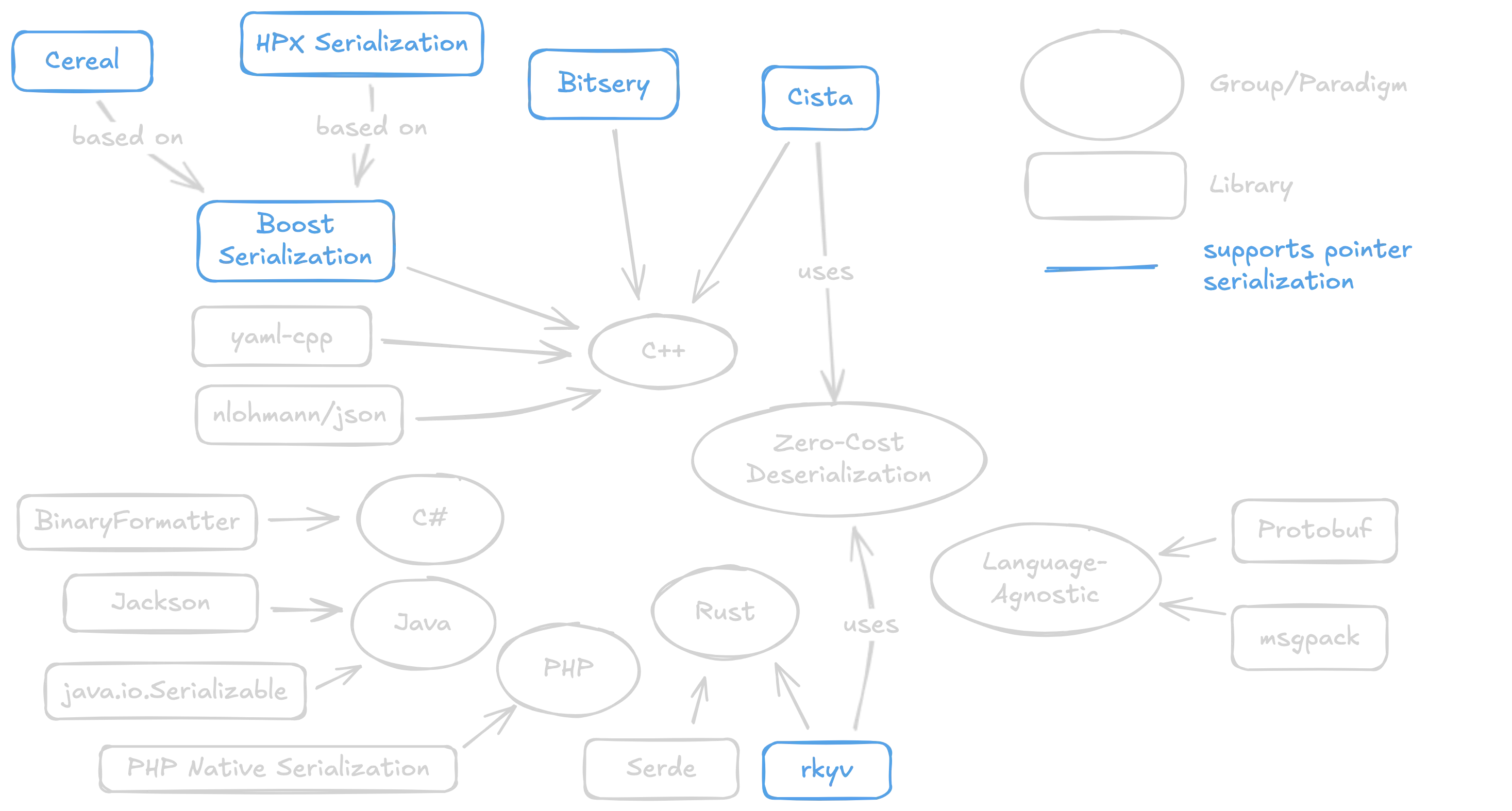
A non-exhaustive mindmap of our target libraries and how they fit within the ecosystem. We are primarily interested in libraries which support pointer serialization.
It's worth noting that the attack approach is unlike well-known attacks on BinaryFormatter, java.io.Serializable, and PHP native serialization. We do not aim to deserialize arbitrary classes with code execution capabilities. That would be a miracle in a statically-typed language which compiles to native machine code. Rather, we strive to be agents of chaos by conflating pointers and data: Confusion Attacks.
Insecure Deserialization Meets C++ Meets Confusion Attacks
Broadly speaking, a confusion attack exploits some (hidden) ambiguity in a system. Weird things can happen when two or more components disagree on the semantics of a property, variable, or memory region. Weird things which can make your computer explode— or more realistically, allow some remote hackerman into your system.
Taking inspiration from Orange Tsai’s sharing on confusion attacks in 2024, I’ll present a few different avenues for deserialization/confusion attacks along with attack primitives. Unlike Orange, however, I won’t be presenting any new strains of confusion attacks, and I certainly won’t be replicating his prowess or scale.
We'll cover the following today:
- Type Confusion: Exploits the ambiguity in the structure and semantics of memory, ultimately, confusing pointers and data. What if pointers were treated as data? What if apples were pine cones?
- Ownership Confusion: Exploits the ambiguity of pointer ownership. What if we violate ownership and lifetime assumptions?
In the rest of this post, we broadly define Insecure Deserialization of Pointers/References as this:
Insecure deserialization of references occurs when a library (which supports serialization of pointers/references) insecurely deserializes a reference such that an object of one type may be interpreted as a different type (i.e. type confusion).
1. Type Confusion
Type Confusion is realized when memory is interpreted differently by two or more types. It is a story about perspectives, how two friends are arguing about the same object, simply because they see things differently.
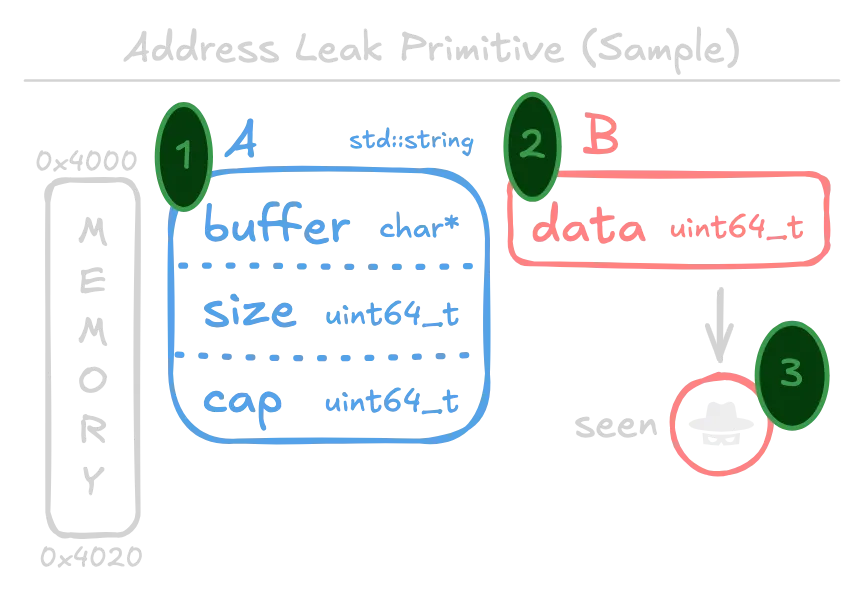
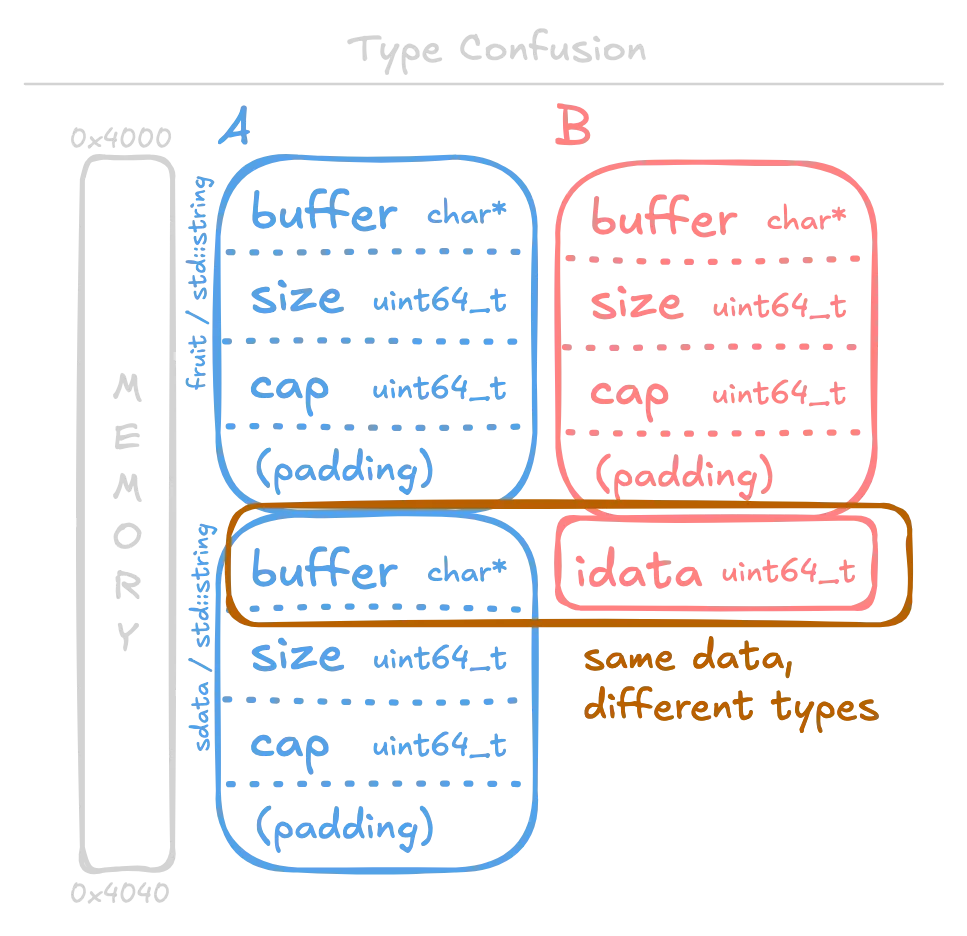
Here’s a simple example. By confusing a string and an integer, it is possible to create ambiguity in the first 8 bytes.

In C++, an std::string is a dynamically-sized character array, which is achieved by storing a pointer to heap-allocated memory. Left: The intended type in memory (what type the bytes were intended for). Right: The confused type (how the program eventually interprets the bytes).
At a very low level, such vulnerabilities boil down to confusion between pointers and data. If pointers are treated as data, there is the potential for address leakage (information disclosure). More severely, if attacker-controlled data are treated as pointers, it could lead to memory read/write and control flow hijacking primitives.
This attack is not new. Type Confusion flaws are common in browser and mobile exploitation, and have been repeatedly discovered in major players such as the V8 JavaScript engine.
Depending on the types confused, we can achieve a variety of primitives and impact. Let’s explore the potential primitives found by confusing common C++ types and structures!
1.1. Address Leak
Address leaks are targeted memory reads useful for bypassing protections such as ASLR and PIE. They provide a starting point to exploit an application.
Conditions:
- Deserialize a type
Awhich contains a pointer memberptr. Examples arestd::string,std::vector, or any polymorphic class— structures which contain a pointer of some sort. - In the same archive, deserialize a type
Bsuch that the pointer memberptris interpreted as a value. - The deserialized object of type
Bis outputted and observable by the attacker (e.g. network request,std::cout, rendered on UI).
Left: The intended type in memory (what type the bytes were intended for). Right: The confused type (how the program eventually interprets the bytes).
The above diagram demonstrates an address leak by confusing an std::string with a uint64_t (64-bit unsigned integer). When the B object is printed, buffer is interpreted as an integer instead of a pointer! If the string is stored as a stack/global variable, a stack/binary address can be leaked with short-string optimization (SSO). Otherwise, a heap address can be leaked.
Concrete Example 🔥: Address Leak
Here’s a simple example where we abuse type confusion for an address leak in Cereal.
Running the program normally, we get the following output and serialized JSON:
The format is fairly straightforward. The values of a, a2, and b correspond to their respective objects. ptr_wrapper is a wrapper for shared pointers. Cereal implements object tracking with the id field. When a shared pointer is first encountered, Cereal sets the id to an incrementing counter plus the MSB 231 (or 1 << 31, 2147483648). Otherwise, when the pointer is reused, the id is set directly without the extra bit flag. In the JSON above, we can see how a2 refers to a with id = 1 and how b is its lonely self with id = 2. Finally, data holds the contents of the underlying object. Simple, right?
Now, suppose an attacker uses a modified JSON archive by adjusting the id field of b.
After deserializing, the output is:
Woah! Big number! We observe b->fruit prints Apple, but b->idata prints a heap address! What happened?
Upon deserialization, a and b share the same memory address. This leads to confusion in the case of the sdata/idata member. When printing sdata, the memory is treated as a string. But when printing idata, the memory is treated as an integer. This "treatment" is bound at compile time due to static typing. Since the first member of an std::string happens to be the string buffer, we get an address leak.
1.2. Arbitrary Memory Read
Conditions:
- Deserialize a type
Aequivalent to auint64_t[2]. - In the same archive, deserialize a type
Bequivalent to anstd::string(or other buffer-like structure) such that it shares memory with the first object. - The deserialized object of type
Bis outputted and observable by the attacker.
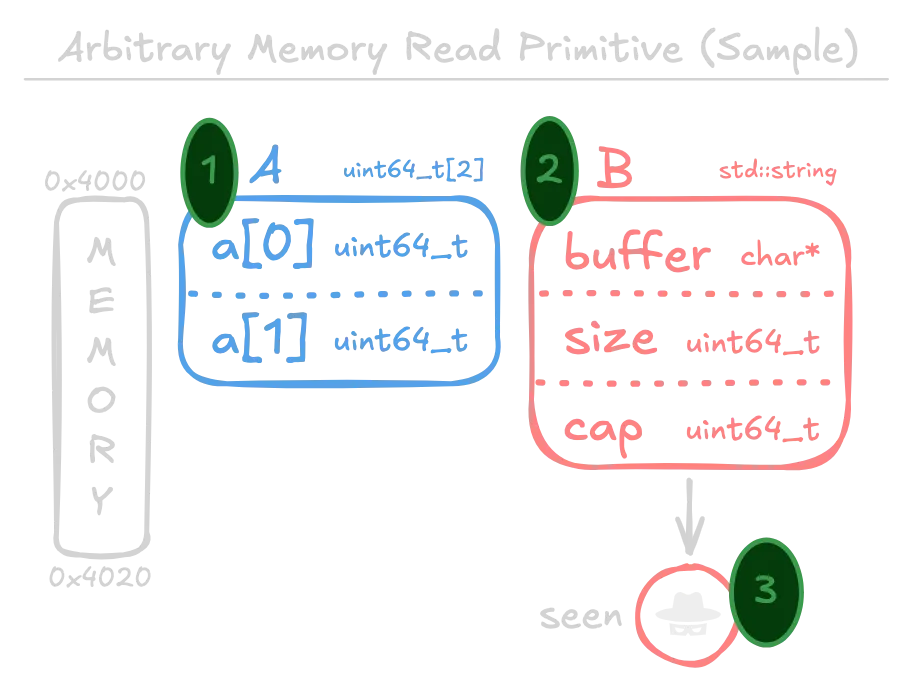
Left: The intended type in memory (what type the bytes were intended for). Right: The confused type (how the program eventually interprets the bytes).
Under this scenario, it is possible to read arbitrary memory by controlling the first two members of type A, which correspond to the string buffer and size in type B. Controlling the third member may be important if the string is later modified (because then capacity is checked for possible resizing).
The diagram and conditions are portrayed with gcc/x64 in mind.
1.3. fakevtable (Control Flow Hijacking via Fake VTables)
Conditions:
- Deserialize a type
Aequivalent to auint64_t. - In the same archive, deserialize a polymorphic (virtual) class
Bsuch that it shares memory with the first object. - The deserialized object of type
Bhas a virtual function which is called.
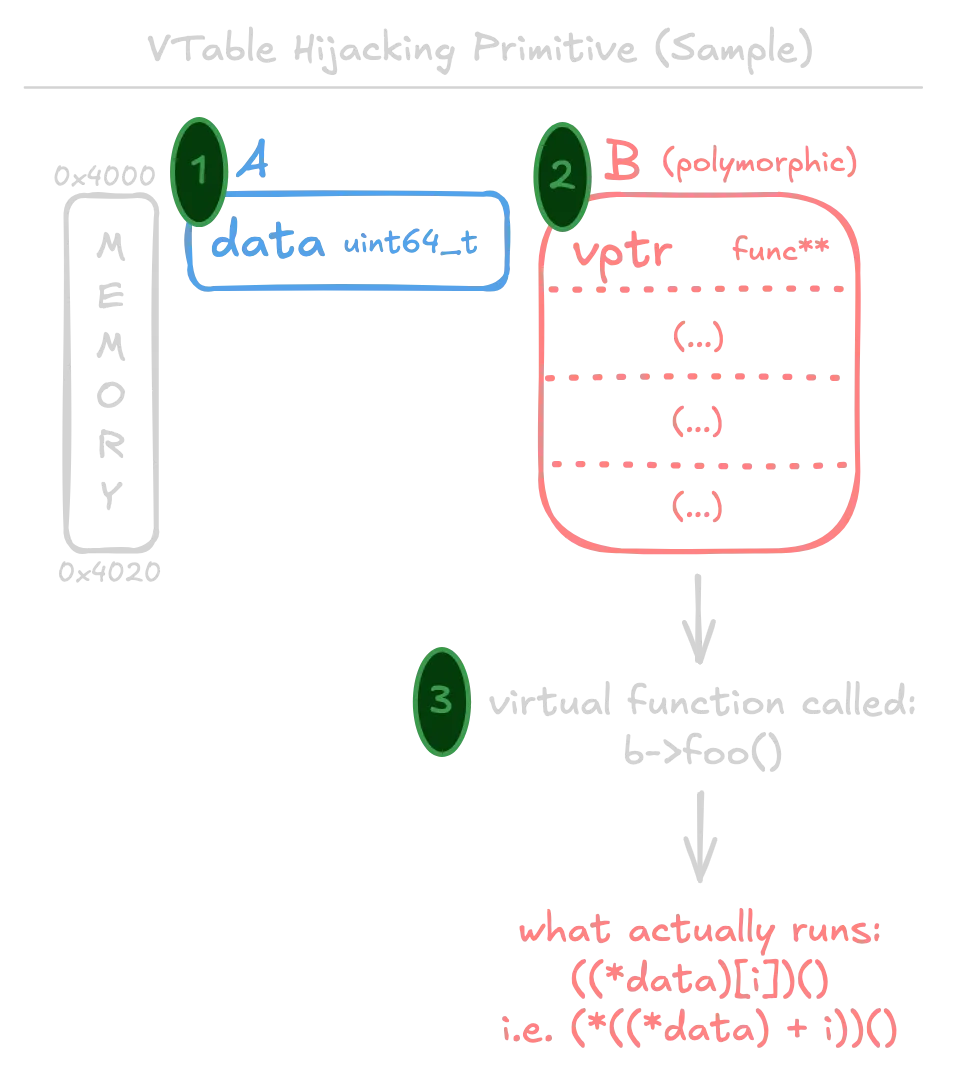
Left: The intended type in memory (what type the bytes were intended for). Right: The confused type (how the program eventually interprets the bytes).
Under this scenario, it is possible to hijack control flow by controlling a v-pointer. When the virtual function is triggered, a double dereference is performed on the v-pointer to obtain a function address, which is then called.
What is a vtable?
To first understand the fakevtable primitive, we need to understand virtual classes, which is a feature of C++. I won't explain polymorphism and virtual classes in detail, but here's a refresher on the low-level implementation:
- Each virtual class has one corresponding virtual table (vtable).
- The vtable stores an array of virtual functions.
- Each object of a virtual class holds a virtual pointer (vpointer) which points to the vtable they are instantiated with. The vpointer precedes other members.
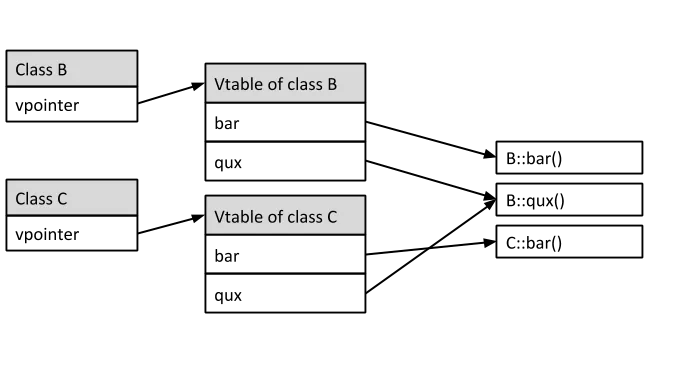
Example of two objects of a base class B and a derived class C. Credit: Pablo Arias
When a virtual function is called, dynamic dispatch is carried out by looking up the vtable then jumping to a function at a hard-coded offset. In assembly, this could be seen as a double dereference.
That's... pretty much it. For further reading, check out: StackOverflow and Understanding Virtual Tables in C++ by Pablo Arias.
So how do we exploit this? There are two common ways:
- "Fake" the vpointer. If we can control the vpointer, we can direct it to an arbitrary vtable (one that we potentially control).
- Overwrite a vtable entry. This requires some sort of arbitrary write primitive.
On the next virtual function call, our fake entry will be triggered which would allow us to call functions and gadgets for total carnage!
Concrete Example 🔥: fakevtable
Similar to the Address Leak example, we'll start with some Cereal code:
Let's run this cleanly once to see what the archive and output look like.
Now let's run this again but hijack control flow using type confusion!
Output:
We successfully redirected control flow to the pwned function!

The code is slightly contrived in that we hard-coded a shell function, fake vtable, and address leak. But these can all be accomplished through other means.
1.4. Arbitrary Code Execution (ACE)
We can use the above three primitives to achieve code execution! Here's the rundown:
- Leak a binary/stack/heap address to bypass PIE/ASLR. This provides a foundation for further exploits. Now we can query nearby addresses to gain more information. (Primitive 1.1)
- Leak a libc address, libstdc++ address, and possibly other details. A libc address helps us locate gadgets. (Primitive 1.2)
- Craft a "fake vtable" containing a sneaky little gadget chain.
- Confuse the vpointer to hijack control flow. When a virtual function is called, our gadget chain is triggered. (Primitive 1.3)
A detailed example and walkthrough is provided in my earlier post “Sharing is Caring: Arbitrary Code Execution for Breakfast”, where I shared a CTF challenge with the goal of obtaining RCE on a simple program written with Cereal.
For context, here is the vulnerable code; try to figure out how to obtain the primitives :).
2. Ownership Confusion Leading to Heap Corruption in Boost Serialization
Ownership Confusion is realized when an ownership model is violated at runtime.2 For instance, pointers with a unique ownership model are instead shared, which may lead to heap corruption vulnerabilities such as double-free or use-after-free (UAF). These open the door to further exploitation, potentially leading to ACE.
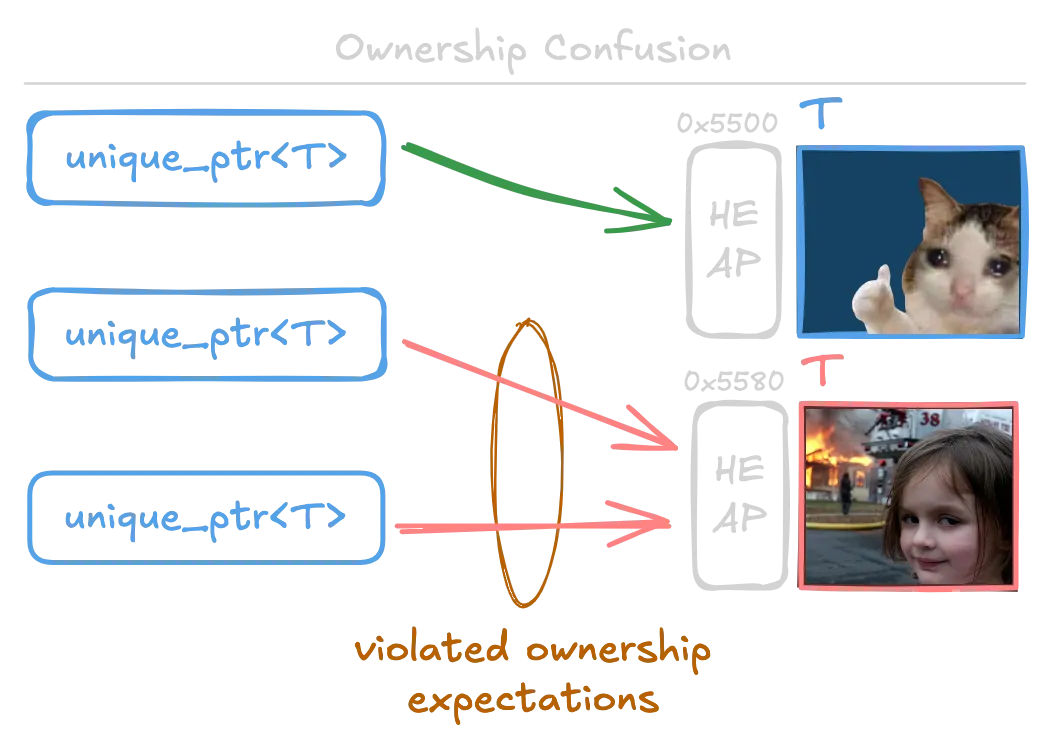
Conditions:
- Deserialize multiple objects of type
unique_ptr<A>(or of similar semantics), internally pointing to the same memory.
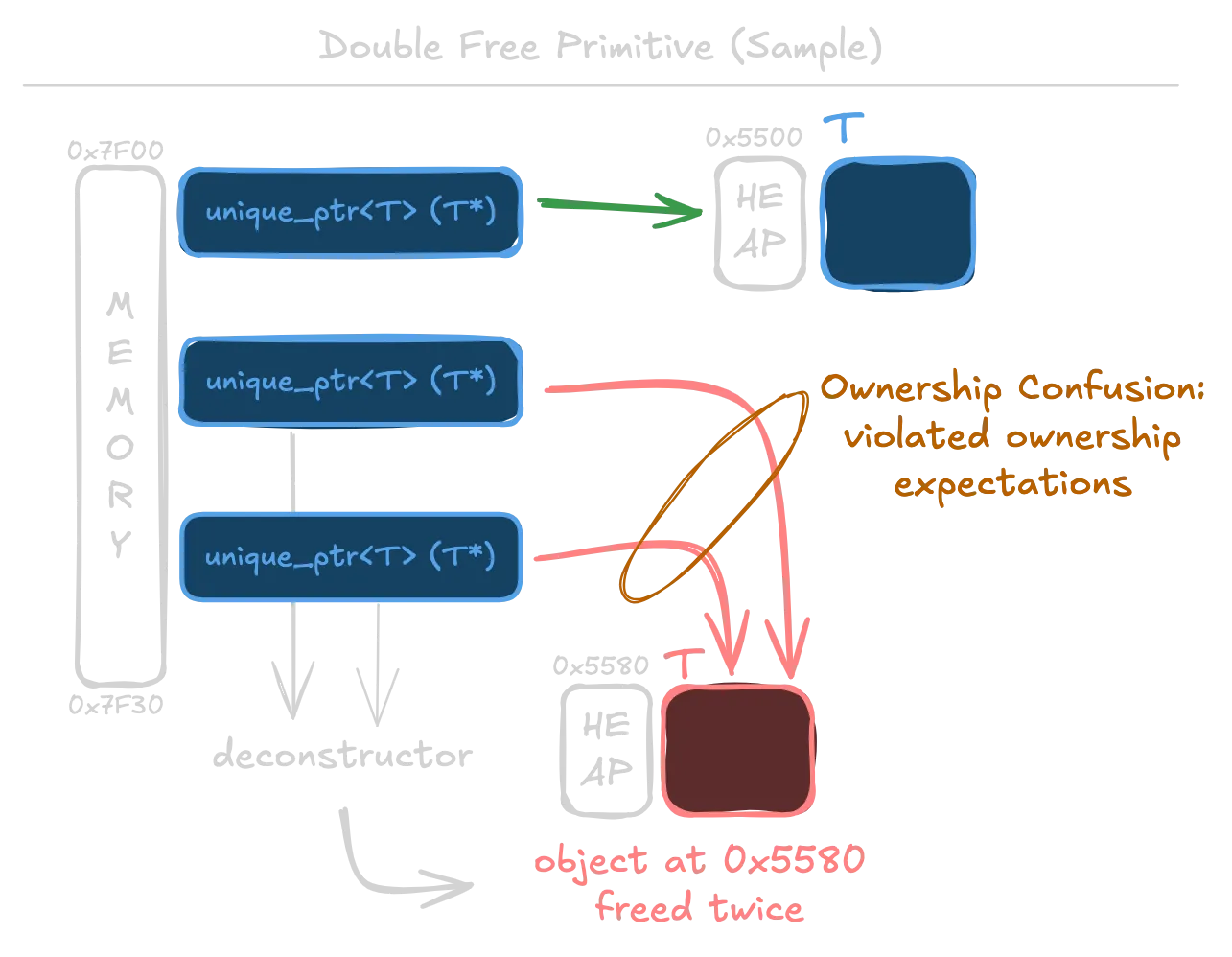
Normally, only one unique pointer should own a resource. (The resource's owner is unique.) In the diagram above, that is represented by the object at 0x5500. But when multiple unique pointers hold the same object (0x5580), that object will be freed multiple times!
One scenario where this could be exploited is with a container of unique pointers such as vector<unique_ptr<T>>.3
Boost's deserialization of unique pointers are also prone to this heap corruption. The root cause is the object_id property. Using object_id, any deserialized pointers can be forced to have shared ownership semantics.
Concrete Example 🔥: Double Free
This time, instead of serializing shared_ptr, we'll be serializing its cousin the unique_ptr.
Running produces the following output and XML archive:
But what if we modify the archive so that the second object refers to the first?
Boom!
In this case, the double free was caught by protections available in recent libc versions. But it's not game over yet! It is possible to bypass these protections, say if we have control over the number and order of deserializations (e.g. std::vector<std::unique_ptr<T>>). I’ll leave this as an exercise for the reader.
3. Type Confusion Leading to Address Leak in Cista (Zero-Copy Deserialization)
Among the five affected libraries, Cista is unique for featuring zero-copy deserialization. Instead of parsing and unpacking bytes, the library performs a type cast on the allocated memory and voilà, the data can be used directly. This enables faster deserialization while sacrificing payload size and requiring custom types.
Cista supports two different archive formats: cista::offset and cista::raw. Both are binary formats and serialize to the same output, but their difference lies in whether pointer resolution is deferred. cista::offset defers pointer resolution. Every time data is accessed, an extra addition is needed to calculate the pointer. cista::raw does not defer calculation, with the benefit of faster runtime access down the line.
The cista::raw implementation is vulnerable to potential address leakage when deserializing untrusted input. This happens for types such as cista::raw::ptr (weak non-owning reference), cista::raw::string, and cista::raw::vector which internally contain an offset to their boxed data and upon deserialization will update the buffer with resolved pointers.
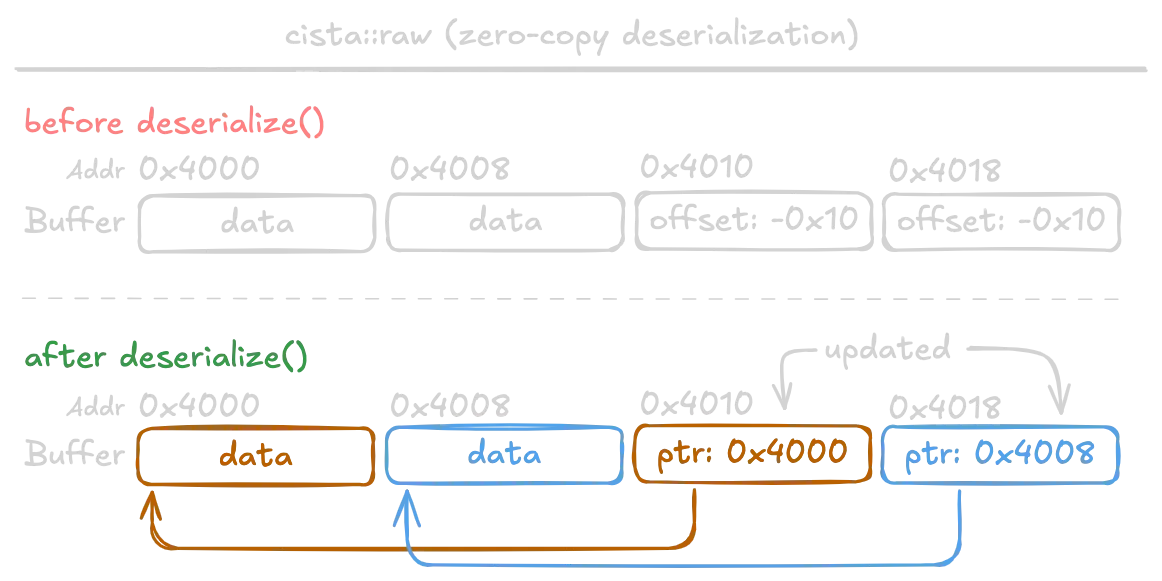
This is a security issue! By mixing pointers and data without clear boundaries, applications may inadvertently treat pointers as data, which may lead to information disclosure such as an address leak. This is type confusion, not in the traditional sense, but in the sense that pointers and data are mixed, and Cista can't tell one from the other.
Conditions for an address leak in Cista:
- Code deserializes an offset-based type under the
cista::rawnamespace. This includesptr(weak non-owning reference),string,vector, and other container types. - The deserialized data is observable by the attacker.
This may leak a heap/stack address which could be used to bypass ASLR.
Consider what happens when we modify the offset to be 0.
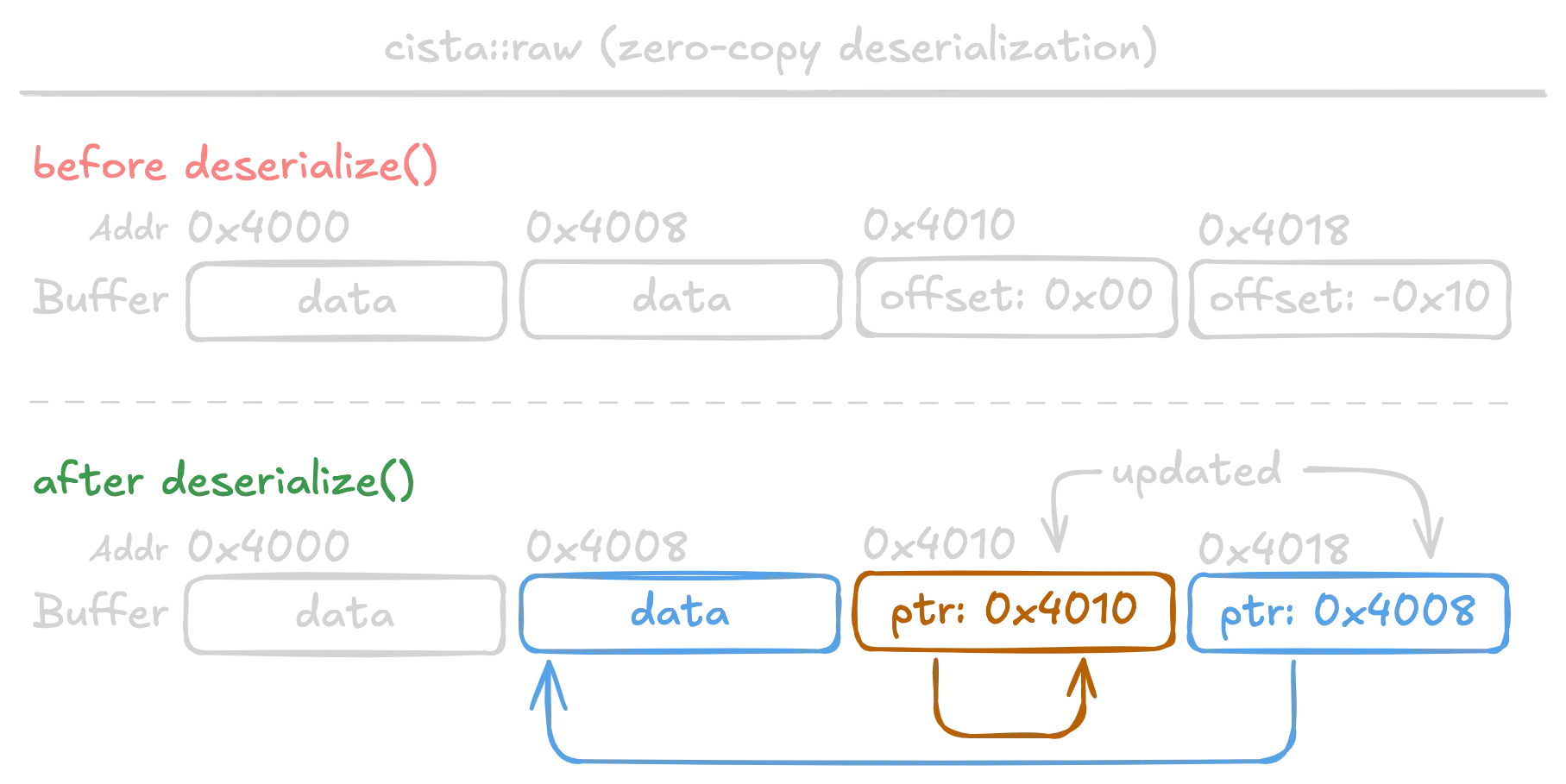
After deserialize() is called, the pointer is updated to itself at 0x4010. So now the pointer is also data.
Concrete Example 🔥: Address Leak in Cista
Here's a quick example. Suppose we're serializing a cista::raw::ptr.
The serialized output is 16 bytes. The first 8 bytes stores 42 in little endian. The last 8 bytes stores an offset (-8) to the first 8 bytes, in two's complement. This is Cista's referencing mechanism.
Once we deserialize this buffer, cista::raw will replace the offset with a memory address. If the internal buffer address was at 0x555590abcde0, we would see the following replacement:
When trying to read the data at pa, Cista will dereference the pointer 0x555590abcde0 to get the number 42.
Now, suppose we set the offset to 0 instead of -8. What happens?
Upon deserialization, the last 8 bytes would be replaced with the address of the same 8 bytes (a pointer to itself). User code wouldn't know any difference and deserialized->pa->x would contain an address.
When trying to read the data at pa, Cista will dereference the pointer 0x555590abcde8 and get the number 93825987759592. The data is the pointer!
Full Sample Code
Output:
Is this really a vulnerability in the library? Who bears the burden of fixing?
I'm aware this discussion may arise, and I've somewhat had this discussion with the maintainer, to little effect. But mostly I'm writing this section to quell some of my own doubts and articulate my view. Here's the thing...
Suppose you're a library user, happily downloading and using Cista for your next project. You write some dumb app using GPT and ensure all the secure configurations are enabled. For instance, you use Cista's DEEP_CHECKS template option when deserializing, which ensures that pointers are not out-of-bounds, and there are no potential cyclical traps which may lead to DoS.
The library's documentation reassures you that it is safe to deserialize untrusted input. So you build your dumb app and expose it to the wild forces of the internet.
Some time later, some dumb black hat throws a bunch of bytes at your dumb app and hacks it. Turns out, the hacker replaced 0xf8,0xff,0xff,0xff,0xff,0xff,0xff,0xff with 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00. When those bytes were deserialized, the library returned a value, a heap address, which your application code trusted to be application data. As your code chugged along, it inadvertently exposed that heap address, reducing entropy for the attacker and allowing them to bypass ASLR, which then allowed the hacker to pull off other fancy attacks affecting some other component.
What does this mean for the library user? That they can't trust Cista's deserialized output? That they need to perform their own checks?
No. A serialization library which claims to be safe against untrusted input should draw clear boundaries and provide data the user can reasonably trust. A serialization library definitely should not confuse an internal address (or other metadata) for user data. And it certainly should not weaken the security posture of the application by mixing application data and pointers.
If a field was some bounded integer (e.g. limited to 0 to 5), then a bounds check should be performed by the library user. If not, they expose themselves to integer overflow or negative indexing bugs and the burden is on them.4
But not all integer fields are bounded. Think: ID numbers, a counter, a length, bitwise flags. In these cases, the burden is on the library code as the library user truly has no control. Who's to say 93825987759584 (0x555590abcde0) isn't someone's real ID or phone number?
Admittedly, this issue is not as severe or impactful as the previous two. Still a vuln/weakness nonetheless.
4. Bonus: Type Confusion Leading to Address Leak in rkyv unsafe API
rkyv (pronounced archive, ar-kive) is a Rust zero-copy deserialization library featuring the serialization of shared pointers (std::rc::Rc). It is possible to achieve type confusion in rkyv, similar to the one found in Cista.
The reason for presenting this section is twofold: to demonstrate that such type confusion attacks are not limited to C++ but are feasible in other languages, and to demonstrate that the attack surface isn't solely limited to the library. Just because a library offers a secure configuration does not mean research has hit a dead end. What if some devs obliviously disabled this secure configuration while accepting untrusted input? There is the potential for downstream applications to be “misconfigured”.5
It should be noted that rkyv has a secure configuration (the default safe API) to mitigate this potential vulnerability. The library also provides an unsafe API, presumably for developers who want to opt for speed. The burden is on the library user to decide between security and performance.
Alright, enough yapping. Let's demonstrate a scenario where a library user "misconfigures" rkyv.
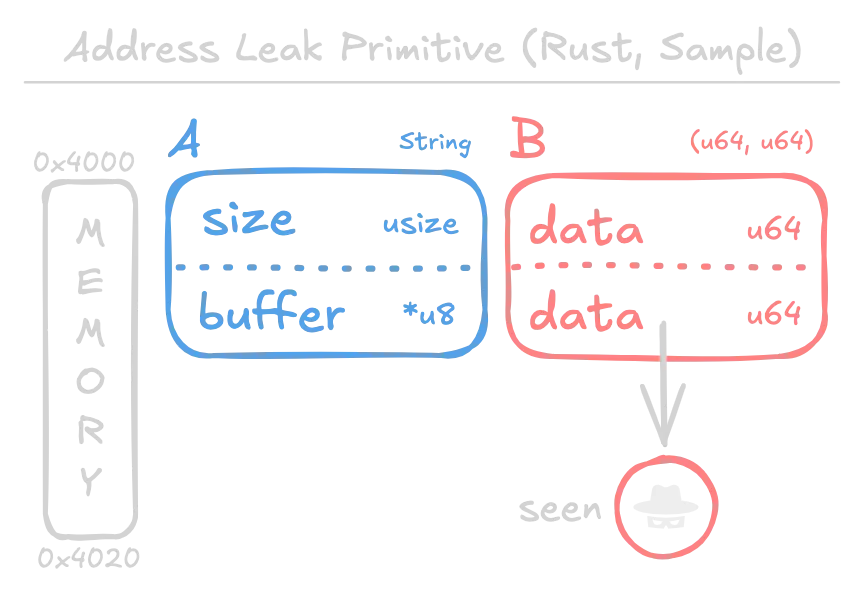
To call the vulnerable API, we need to use Rust's unsafe {} wrapper. In the following example, we will deserialize shared pointers to a String and (u64, u64) (pair of 64-bit unsigned integers). Again, we assume the deserialized result is observable by the attacker. The goal is to leak the String's internal buffer address.
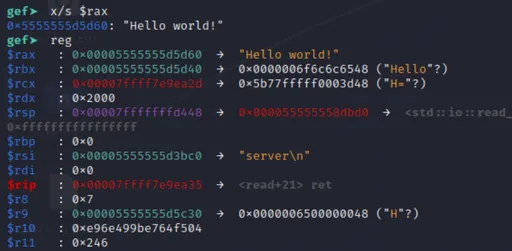
Running this, we observe an address leak:
Rust, on x86 Linux, represents a String with the size in the first 8 bytes followed by the address. Here, we see the size is 5 (corresponding to the string hello) and the leaked heap address is 0x55aecbf81e30.
Full Code
Advisory
Insecure deserialization of pointers under certain conditions may lead to type confusion, resulting in potential information disclosure, control flow hijacking, and arbitrary code execution.
Affected Software
The following libraries are affected, with the assigned CVEs.
| CVE | Library | Affected Versions | Status |
|---|---|---|---|
| CVE-2026-11460 | Boost Serialization | All Known Versions (1.91.0 and below) | No patch available. Maintainer acknowledged but postponed indefinitely citing time concerns. See workarounds below. |
| CVE-2026-11463 | Cereal | All Known Versions (1.3.2 and below) | No patch available. Unable to reach maintainer. See workarounds below. |
| CVE-2025-60887 | Cista | All Known Versions (0.16 and below) | No patch available. Maintainer cites low impact and priorities. "Reading untrusted data is not [the maintainer’s] use case", despite the library claiming to be safe against untrusted input. See workarounds below. |
| CVE-2026-9521 | Bitsery | 5.2.4 and below | Fixed in 5.2.5. |
| CVE-2025-60889 | HPX | All Known Versions (1.11.0 and below) | Patch available in pull request. |
Exploit Conditions
Successful exploitation depends on various factors, but the main concerns are the types deserialized and their order. Any mention of "under certain conditions" refers to this section on exploit conditions. Code reviewers and testers should pay attention to the following:
- For Boost Serialization, Cereal, Bitsery, and HPX, deserializations† of a type
shared_ptr<A>followed by a typeshared_ptr<B>are at risk. This applies to bothstd::shared_ptrandboost::shared_ptr. - Additionally, for Boost Serialization, deserializations† using the XML Archive of any type
Afollowed by a pointer type††Pare at risk. Deserializations using Text/Binary Archives of a pointer type††Pfollowed by a pointer type††Qare at risk. - Additionally, for Bitsery, deserializations† of raw pointers (
PointerObserver) are at risk. - For Cista, deserializations† using offset-based types from the
cista::rawnamespace are at risk. Offset-based types are types which contain an internal offset pointer and include but are not limited tostring,vector, andptr.
†: Deserializations occurring within the same archive.
††: Pointer types include raw pointers, std::unique_ptr, std::shared_ptr, along with their Boost variants.
PoC
For a demonstration of a full exploit chain from address leak to RCE, check out the breakfast CTF writeup.
I've also uploaded a couple CTF challenges and examples for each affected library.
Impact
The table below shows the potential impact a library faces.
| CVE | Library | Information Disclosure (Address Leak) | Information Disclosure (Memory Read) | Arbitrary Code Execution |
|---|---|---|---|---|
| CVE-2026-11460 | Boost Serialization | √ | √ | √ |
| CVE-2026-11463 | Cereal | √ | √ | √ |
| CVE-2026-9521 | Bitsery | √ | √ | √ |
| CVE-2025-60889 | HPX | √ | √ | √ |
| CVE-2025-60887 | Cista | √ |
√ = Potential Impact
- Information Disclosure (Address Leak): Under certain conditions, it is possible to disclose memory addresses which may be used by malicious actors to bypass protections such as ASLR and PIE. If the library is part of the kernel, it may lead to a KASLR bypass. Minor loss of confidentiality.
- Information Disclosure (Memory Read): Under certain conditions, it is possible to read arbitrary memory. Huge loss of confidentiality, under the majority of contexts.
- Arbitrary Code Execution: Under certain conditions, it is possible to execute arbitrary code. On a macro scale, this may lead to LPE or RCE depending on the nature of the downstream application. For instance, if the archive is passed and deserialized via IPC or a file, the system is potentially vulnerable to LPE. If the archive is deserialized over the network such as RPC or an HTTP API, the system is potentially vulnerable to RCE. Huge loss of confidentiality, availability, and integrity.
Mitigations and Workarounds
- Some libraries currently have no fix available despite communication with maintainers.
- Workaround: Use alternative, non-referential data types which have simpler deserialization routines. This may impact performance due to extra conversions. For instance, instead of serialising a
vector<A*>, use a flatvector<A>of unique objects and avector<size_t>containing indexes to the first vector. - Detective Controls: Monitor untrusted channels. If the serialization payload comes from a file, this may mean logging and auditing file writes for potential unauthorized uploads or unexpected path traversal attacks. If the payload comes from a network, this may mean whitelisting/auditing connection sources and strengthening authentication (e.g. IP whitelisting).
- Library-specific advice:
- For Boost Serialization, avoid deserializing multiple pointers within the same archive.
- For Cista, consider using types from the
cista::offsetnamespace instead ofcista::raw.
Timeline
| CVE | Library | Discovered | Reported to Vendor | Reply from CNA | Published by CNA |
|---|---|---|---|---|---|
| CVE-2026-11460 | Boost Serialization | 2025.08.02 | 2025.08.08 | 2026.06.07 | 2026.06.07 |
| CVE-2026-11463 | Cereal | 2025.08.06 | 2025.08.08 | 2026.06.07 | 2026.06.07 |
| CVE-2025-60887 | Cista | 2025.08.26 | 2025.08.27 | 2025.10.17 | 2026.04.28 |
| CVE-2026-9521 | Bitsery | 2025.08.30 | 2025.08.30 | 2026.05.26 | 2026.05.26 |
| CVE-2025-60889 | HPX | 2025.09.03 | 2025.09.03 | 2025.10.17 | 2026.04.28 |
Root Cause Analysis
Earlier, I posed the question "What is a mechanism to exploit?", to which our answer was serialization of references. Under the hood, this often boils down to a simple shallow copy (aka a pointer copy, new_ptr = old_ptr) which skips further deserialization. In general terms, it can be expressed with the following pseudocode:
But the shallow copy isn't the issue. It's the fact that this shortcutting step does not check the current type being deserialized.
Shallow Copy Shortcutting Mechanism: The Gory Details
Each library has their own codepath and implementation. In the snippets below, pay attention to the absence of type checks prior to the shallow copy.
Boost Serialization:
- If tracking is enabled and the object was found, then
track()copies the raw address andload_pointer()returns early. - Steps:
- Shallow Copy:
basic_iarchive_impl::track#L360-364 - Early Return:
basic_iarchive_impl::load_pointer#L476-478
- Shallow Copy:
Cereal:
- If the
iddoes not have the special2 << 30flag, then a previous ID is looked up and copied. - Steps:
Bitsery:
- Bitsery will lookup an entry in
_idMap. ForSharedOwnerownership, it will first create and register asharedStateobject, which is later assigned to every instance with the sameid. - Steps:
HPX:
- Despite having a different format, HPX follows a similar lookup-shortcut pattern.
- Steps:
- Lookup:
tracked_pointer#L56-64 - Shortcutting:
serialize_pointer_tracked#L282
- Lookup:
To remediate, one idea is to use a hashmap map<intptr_t, typehash> mapping a raw pointer address to a type ID/hash. On the first encounter, the object is deserialized and the pointer-typeID pair is inserted into the map. On subsequent encounters, the library checks whether the type hash of the stored object equals the type hash of the current deserialized object. Only then is the shallow copy executed.
Patching our pseudocode example:
What about polymorphism? This is a feature implemented in some libraries in this study. To handle polymorphism, we need to redefine (overload) type-equality for polymorphic classes. Instead of checking A == B, we want two classes A and B to be equal if either A > B (B is a subtype / derived class of A) or vice versa. This means we would need to traverse the inheritance chain.
Root cause analysis of Ownership Confusion in Boost Serialization and of Type Confusion in Cista have been left as an exercise for the reader.6
Concluding Notes
On Vulnerability Scoring
CVSS is actually terrible at scoring these vulnerabilities due to the conditions involved. CVSS assumes reasonable conditions required for successful exploitation and further assumes a reasonable "worst-case" scenario as warranted by the CVSS guidelines and examples for software libraries. By scoring according to CVSS, you would realise that a lot of them net a 9.8 Critical (in CVSS v3.1), assuming reasonable worst case. Do these vulnerabilities actually warrant a 9.8 Critical though? Depends who you ask.
VulDB oddly scores it for Low Impact, which I disagree with, but it appears there is no way to appeal how it is scored.
If we were discussing risk, exploitability, and overall real world impact, I would say these vulnerabilities are not a critical 9.8. But the CVSS system does not measure systems this way. CVSS measures severity, not risk. When applied to downstream libraries, applications, and deployments, the risk and severity should be analysed independently.
The point is, CVSS has its pros and cons. CVSS is a rubric, and rubrics are models to quantify the unquantifiable. All models are wrong, but some are useful.
On Memory Safety and Rust
“Would Rust have fixed this?”
Perchance? Maybe? Not really?
To be fair, Rust does its part in eliminating integer overflow (a whole class of runtime bugs!) by encouraging checked arithmetic. But unlike checked arithmetic, the deserialization attack surface is much more varied and dynamic, with complex types and logic. Thus, to secure serialization of references, type checks need to be explicitly programmed by the library author.
rkyv, a Rust serialization library discussed earlier, exposes two APIs: an unsafe API prone to type confusion attacks, and— more notably— a safe API with extensive runtime type validation. If rkyv is deemed "more secure" against deserialization attacks, it would be thanks to its validation modules rather than Rust itself. Perhaps the case could be made that Rust fixes the issue by proxy of promoting a security-first mindset. But whether this is effectively executed (in general) depends on a developer's decisions.
Further Research
Some ideas for further research:
- Relax or find alternative conditions for exploitation. Current conditions require deserialization of certain types (e.g.
shared_ptr) to obtain primitives. - Further research on potential impact in downstream software, of which there are two types:
- Dependents of the affected libraries, exploiting the CVEs explained in this post.
- Dependents of serialization libraries exploiting insecure configurations (e.g. cista/rkyv without validation). It is possible that library users have security configurations disabled, inadvertently opening the door to attacks. In such cases, this would be a vulnerability in the library users' code rather than in the library itself.
- Further research on similar attacks in other languages/libraries.
Stay frosty. Keep hacking.
Footnotes
Interestingly, some researchers take the opposite approach by considering the serialization API an attack surface. Here, a successful attack scenario usually involves rare preconditions of uninitialised data or type narrowing/widening issues which I guess would assume the developer doesn't read documentation, doesn’t properly test their code, or is actively sabotaging their software. It means an attacker needs to control the data prior to serialization. These are still scored as critical issues, to the chagrin of library authors. Examples are CVE-2020-11104, CVE-2020-11105 (Cereal), CVE-2024-35326 (libyaml) (rejected). ↩︎
One can argue this is a gimmick for heap corruption, but there is a subtle difference. :P I use "ownership confusion" because I think "heap corruption" describes the situation inaccurately. Let me reword that: heap corruption is the impact (or perhaps more accurately, an intermediate primitive?), but the attack itself targets memory/lifetime assumptions and doesn't directly target the heap. Ultimately, this is a confusion attack on lifetime semantics. ↩︎
It is also possible to achieve a use-after-free (UAF) primitive if a second object remains active after the first one is deleted. ↩︎
This could potentially be solved by the library providing a BoundedInteger type which will perform runtime checks upon deserialization. ↩︎
Relevant to this discussion is: How do we define trust? What about attack payloads delivered locally over the filesystem? Food for thought. ↩︎
"Since you've root-caused analysed the problem, why don't you submit a patch?" Easier said than done. Fixing such a bug requires non-trivial changes to the code structure. For some libraries such as Boost Serialization, it may require tough decisions, possibly dropping support for raw pointer serialization all together. For what it's worth, I have submitted a PR fixing an old Boost Serialization CVE, but it remains to be merged, which I think says something about the ecosystem. ↩︎
Related Posts

Sharing is Caring: Arbitrary Code Execution for Breakfast
A CTF challenge exploring binary exploitation in C++, gadget mania, and a new form of deserialization attack.

When Hospitality Software is Too Hospitable (CVE-2026-21966, CVE-2026-21967)
An XSS Filter Bypass and a Curious SSRF in Oracle Hospitality OPERA

Reverse Engineering a Siemens Programmable Logic Controller for Funs and Vulns (CVE-2024-54089, CVE-2024-54090 & CVE-2025-40757)
When security by obscurity breaks...


Related Tags
software.security
advisory ctf infosec reverse pentesting pwn cve cryptography redteam stegoComments are back! Privacy-focused; without ads, bloatware 🤮, and trackers. Be one of the first to contribute to the discussion— before AI invades social media, world leaders declare war on guppies, and what little humanity left is lost to time.